|
|
|
![]()
![]()
![]()
1.1 Eine "herkömmliche" Web-Site
1.1.1 Vorbemerkung
Dieser Abschnitt erfüllt nicht den Zweck einer grundlegenden Einführung in das World Wide Web oder gar das Internet. Dies würde den Rahmen dieser Arbeit sprengen. Vielmehr sollen die technischen Grundlagen, auf denen die Informationsverteilung im World Wide Web basiert, kurz zusammengefaßt werden. Es wird jeweils für weiterführende Informationen auf entsprechende Quellen verwiesen.
Es ist wichtig, die Funktionsweise einer "herkömmlichen" Web-Site zu verstehen, um die Vorteile und Konsequenzen beurteilen zu können, die sich durch den Einsatz von Datenbanken in diesem Zusammenhang ergeben.
1.1.2 Das World Wide Web
Der grundlegende Aufbau des World Wide Web (WWW, Web, W3) unterscheidet sich nicht von anderen Internetdiensten, er basiert auch auf einer Client/Server-Architektur. Dokumente auf Servern werden in einem bestimmten Format, im Falle des WWW einem Hypertext-Format, abgespeichert. Mittels geeigneter Clients, sogenannten "Browsern", wird auf die Dateien zugegriffen, die auf dem Server vorhanden sind. Client und Server verständigen sich untereinander via TCP/IP-Netzwerke (Internet oder LAN) über das HTTP-Protokoll (Hypertext Transfer Protocol). Die Hypertext-Dokumente werden im HTML-Format, der HyperText Markup Language, angelegt. WWW-Browser stehen für alle gängigen Hardware- und Betriebssystem-Plattformen zur Verfügung, z.B. Netscape Navigator, Microsoft Explorer, Mosaic, Lynx.
In solchen "herkömmlichen" Web-Sites, die heutzutage die überragende Mehrheit der Informationsangebote im Web ausmachen, liegen alle Informationen in statischen HTML-Seiten vor, die abgerufen und auf dem Browser angezeigt werden.
Weiterführende Informationen:
1.1.3 Hypertext Markup Language (HTML)
Ein HTML-Dokument ist ein einfaches Textdokument, das in eckige Klammern eingeschlossene Steuerkommandos, sogenannte "Tags" enthält. Der WWW-Client interpretiert diese im Text eingebetteten Tags und stellt das so formatierte Dokument dar.
Jedes HTML-Dokument beginnt mit dem Tag <HTML> und endet mit </HTML>. I.d.R. beginnen HTML-Anweisungen mit einem öffnenden
Tag der Form <Name Attribut=Wert> (auch mehrere oder keine
Attribut/Werte-Paare möglich) und werden mit einem schließenden
Tag </Name> beendet.
Ein HTML-Dokument gliedert sich in zwei Teile:
dem <HEAD> und dem <BODY>. Der <HEAD> enthält generelle Informationen über das Dokument wie
z.B. den <TITLE>. Der eigentliche Inhalt befindet sich im <BODY>.
Die HyperText-Funktion erfolgt über das <A> (Anchor) Tag. Mit dem Attribut
HREF (HyperText Reference) wird eine lokale Datei oder ein URL
angegeben, zu der bzw. dem der Link führen soll. Der
anschließende Text bis zum Abschluß-Tag </A> stellt den anklickbaren Link dar.
Bsp.: <A
HREF="link.html">Hier klicken</A>
Aus dieser Zeile im HTML-Dokument stellt der Web-Browser den durch Unterstreichung und besondere Färbung markierten Text Hier klicken dar. Wenn der Benutzer mit der Maus auf diesen "Hyperlink" klickt, wird die Datei link.html aufgerufen und dargestellt.
Grafiken und andere multimediale Informationen werden durch einen Verweis auf die entsprechende Datei, z.B. eine Grafik im GIF-Format, eingebunden.
Bsp.: <img
src="images/bild.gif">
Ein Browser, der eine HTML-Datei mit dieser Zeile anzeigt, fügt an der entsprechenden Stelle die Grafik ein. Der Pfadname bezieht sich auf das Dateisystem des Servers, und zwar relativ zu dem Verzeichnis, in dem sich die HTML-Datei befindet. Es können auch absolute Pfadangaben und URLs verwendet werden.
Weiterhin gibt es Tags zur Strukturierung und Gliederung der Dokumente, zur Textformatierung (fett, kursiv, Überschriften, Tabellen, Listen) sowie zum Einfügen von Sonderzeichen, Grafiken und Java-Applets.
1.1.3.1 Formulare
Ein wichtiger Teilbereich von HTML sind die Tags zur Darstellung von Formularen. Sie ermöglichen es, Benutzerschnittstellen zur Dateneingabe für interaktive Anwendungen im World Wide Web zu gestalten. Mit Hilfe dieser Tags können in einer HTML-Seite Textfelder, Auswahllisten, Radiobuttons, Checkboxen und Buttons dargestellt werden.
<HTML> |
Die HTML-Datei in Listing 1 stellt in einem Web-Browser ein Formular wie folgt dar:
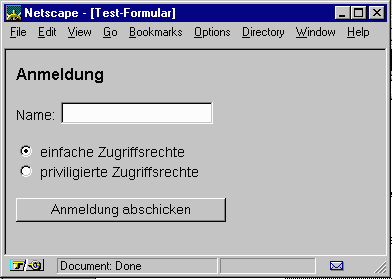
Abbildung 1: Formulardarstellung mit Netscape Navigator
Nachdem der Benutzer seinen Namen in das Feld eingetragen und seine Zugriffsrechte gewählt hat, betätigt er den mit "Anmeldung abschicken" bezeichneten sog. "Submit-Button", um die Eingabe abzuschließen. Dies bewirkt, daß der Browser einen neuen Request an den Server stellt, der aus dem im Attribut "ACTION" des "FORM"-Tag angegeben Programms sowie einer Reihe von Parameter/Wert-Paaren besteht, die das angesprochene CGI-Programm auslesen kann. Die Parameter-Namen ergeben sich aus den NAME-Attributen der Formularelemente, die Werte aus den entsprechenden Benutzereingaben. Genaueres zu Codierung und Datenübertragung zwischen Web-Browser und CGI-Programm erfahren Sie in [W6].
1.1.3.2 Versionsproblematik
Der HTML-Standard wird ständig weiterentwickelt. In den letzten zwei Jahren gab es die Versionen 2.0, 3.0 und z.Zt. (März 1997) die aktuelle Version 3.2. Darüberhinaus haben die beiden marktstärksten Browseranbieter Microsoft und Netscape jeweils eigene und teilweise gemeinsame Erweiterungen des HTML-Standards eingeführt. Dadurch, und da nicht jeder Benutzer immer die aktuellste Version eines Browsers benutzt, stellt sich bei der Programmmierung von HTML-Seiten immer die Frage, welche Tags man verwenden will und welche nicht. Grundsätzlich ist es so, daß ein Browser bei einem ihm unbekannten Tag keine Fehlermeldung erzeugt, sondern diesen Tag einfach ignoriert. Dadurch geht i.d.R. keine Information verloren, aber die Darstellung ist eine andere, als vom Autor der Seite gewünscht.
Eine Ausnahme dieser Regel bilden die sog. "Frames". Sie sind zwar im aktuellen HTML-Standard 3.2 nicht enthalten, werden aber von den meisten aktuellen Browsern (u.a. Microsoft Explorer und Netscape Navigator) verstanden. Sie bieten die Möglichkeit, das Browserfenster in mehrere Frames zu unterteilen, wobei jeder Frame durch eine eigene HTML-Seite gefüllt wird und Querverweise zwischen den Frames gestattet sind. Ältere Browser können solche HTML-Seiten überhaupt nicht darstellen, für sie muß der Programmierer ggf. eine parallele framelose Version der Web-Site bereitstellen.
Aus diesem Grund ist die Verwendung von Frames unter Webmastern umstritten. Für bestimmte interaktive und/oder Datenbank-gestützte Anwendungen können Sie jedoch ein äußerst hilfreiches, u.U. sogar notwendiges Mittel zur Gestaltung der Benutzerschnittstelle sein.
Weiterführende Informationen:
1.1.4 Uniform Resource Locator (URL)
Der URL ist ein standardisiertes Format zur Adressierung von Resourcen im Internet. Er besteht aus mehreren Komponenten: einer Zugriffsmethode, einem Servernamen, ggf. ein Port (Standardport 80 für WWW-Server kann entfallen) und einer Pfadangabe zu einer Datei oder einem Verzeichnis.
Protokoll://Server:Port/Verzeichnis/Datei.html
So liefert z.B. die URL http://www.oneworldweb.de/kalender/kal9701.html
die HTML-Datei kal9701.html im Verzeichnis /kalender
auf dem WWW-Server www.oneworldweb.de.
Die URL-Schreibweise wird auch für andere Internet-Dienste wie
Gopher (gopher://), FTP (ftp://) oder Newsgroups (news://)
verwendet.
Weiterführende Informationen:
1.1.5 Hypertext Transfer Protocol (HTTP)
"The Hypertext Transfer Protocol (HTTP) is an application-level protocol with the lightness and speed necessary for distributed, collaborative, hypermedia information systems."
(Berners-Lee, T. u.a. [W5])
HTTP wird seit 1990 für das World Wide Web als Kommunikationsprotokoll zwischen Web-Browser und -Server verwendet. Es basiert auf einem Anfrage/Antwort Paradigma ("request/response paradigm"). Ein Client (im WWW i.d.R. ein Browser) etabliert eine Verbindung mit einem Server und sendet eine Anfrage in Form eines URL mit weiteren Informationen wie Protokollversion, Anfragemethode und Client-Informationen. Der Server antwortet mit einem Erfolgs- oder Fehlercode, weiteren Informationen wie Protokollversion und Server-Informationen und ggf. den Daten der angeforderten Datei.
Web-Server sind so eng an HTTP gebunden, daß sie oft auch HTTP-Server genannt werden.
Eine bemerkenswerte Eigenschaft von HTTP in Hinblick auf interaktive Web-Anwendungen ist die Zustandslosigkeit, d.h. jeder Kommunikationsvorgang von Anfrage und Antwort ist in sich geschlossen und nach Ablieferung der Antwort auf der Serverseite abgeschlossen. Für eine weitere Anfrage muß eine neue Verbindung etabliert werden und der Server "weiß nichts mehr" von der vorherigen Anfrage oder dem Client. Müssen z.B. zusammengehörende Informationen über mehrere HTML-Formulare vom Benutzer abgefragt werden, so muß eine Applikation die Daten des ersten Formulars zusammen mit einer Identifizierung des Clients zwischenspeichern, um die später zu erhaltenden Daten des zweiten Formulars dem gleichen Client zuordnen zu können, da eine eindeutige Identifizierung des Clients über HTTP nicht möglich ist. Auf diese Problematik werden wir später noch eingehen.
Weiterführende Informationen:
1.1.6 Web-Server
Ein Web-Server ist ein Programm, das auf Verbindungen von Web-Browsern wartet. Bei einem Request (einer Anfrage) erhält es Informationen über die rufende Maschine, prüft, ob es diesen Request akzeptieren oder ablehnen muß, und handelt dann entsprechend. Wird der Request akzeptiert, so versucht das Programm anhand dem vom Browser gelieferten URL die angefragte Datei (oder das Programm) im eigenen Dateisystem zu finden und an den Browser zu übertragen (bzw. auszuführen).
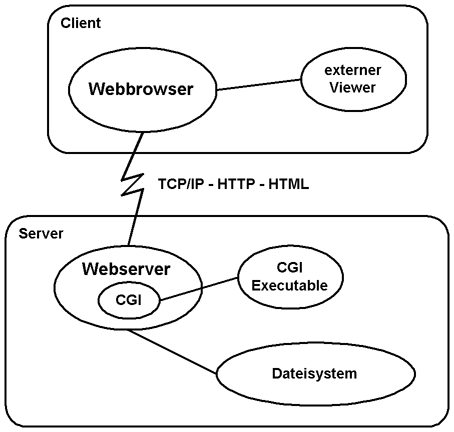
Abbildung 2: Aufbau eines Web-Servers
Ähnlich wie bei den Web-Browsern gibt es inzwischen auch Server für praktisch jede Rechner- und Betriebssystemplattform und mit unterschiedlichem Leistungsumfang. Hier kurz in Stichworten die Grundfunktionalitäten, die jeder moderne Web-Server beherrscht:
Darüberhinaus bieten manche Server einen "sicheren Datenaustausch" mit dem Browser an (SSL, S-HTTP) sowie proprietäre APIs (Application Programming Interfaces) zur Erweiterung der Serverfunktionalität (vgl. Abschnitt 2.1.4) oder die Möglichkeit zur serverseitigen Ausführung von Java-Programmen und Applets oder von JavaScript (vgl. Abschnitte 2.1.7.2 und 2.3.3.2).
Weiterführende Informationen:
1.1.7 Common Gateway Interface (CGI)
Um Informationen darstellen zu können, die nicht in HTML-Form vorliegen, benötigt der Web-Server ein Gateway, das als "Vermittler" fungiert. Client-Requests an das Gateway werden vom Web-Server einfach "durchgereicht". Dieser liefert HTML-Code, einen URL oder andere HTTP-konforme Daten zurück. Wie diese Art der Kommunikation funktioniert, ist mit dem Standard "Common Gateway Interface" spezifiziert.
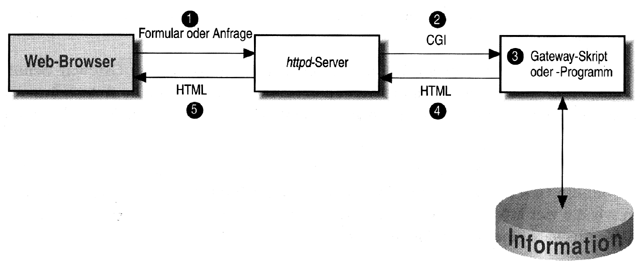
Abbildung 3: Funktionsweise des Common Gateway Interface
Abbildung 3 zeigt den prinzipiellen Informationsfluß zwischen Gateway, Web-Server und Client. Gibt der Benutzer z.B. in einem Formular Text ein und schickt die Daten durch Betätigen eines entsprechenden ("Submit"-) Buttons ab, so sendet der Web-Browser die Eingaben an den Web-Server (1). Dieser nimmt die Eingaben entgegen, startet das Gatewayprogramm und reicht die Eingaben mittels CGI an das Gateway weiter (2). Das Gateway erhält die Tastatureingaben des Benutzers über Umgebungsvariablen (dies ist die sogenannte GET-Methode) oder über die Standardeingabe (POST-Methode). Das Gateway parst die Eingabe und verarbeitet sie (3). Es kann HTML-Ausgabe erzeugen und an den Web-Server zurückgeben (4), der sie wiederum an den Client überträgt (5). Das Gateway kann die Daten aber auch in einer Datei oder Datenbank speichern oder als Email versenden.
Das Gateway kann aus einem Skript oder Programm bestehen, das in C/C++, Visual Basic, Perl, tcl, C-Shell, Bourne-Shell oder irgend einer anderen Programmiersprache, die ein ausführbares File erzeugt und die Standard-Ein/Ausgabe benutzen kann, geschrieben ist.
CGI war lange Zeit die einzige Programmierschnittstelle zur Erweiterung der Funktionalität eines Web-Servers. Die meisten Webanwendungen, die heute im Einsatz sind, basieren auf CGI.
Weiterführende Informationen:
![]()
![]()
![]()
![]()